

Your Azure AI System Is Live. Your Production Control Model Is Not.
Evaluation, monitoring, and auditability are design decisions, not post-deployment fixes.
Section
Table of Contents
- Introduction
- Production AI Control Breaks When Deployment Success Is Treated As Readiness
- Retrofitted Control Becomes Architectural Debt, Not Just Extra Monitoring
- Evaluation Only Works When Acceptable Output Is Defined Before Scale
- Monitoring Fails When It Watches Infrastructure And Misses Behavior
- Auditability Collapses When The Evidence Chain Is Missing
- Control Maturity Depends On Owners, Thresholds, And Release Gates
- Controlled Azure AI Can Prove Quality, Explain Change, And Reconstruct Failure
- FAQs (Frequently Asked Question)
Key Takeaways
- The blog explains why Azure AI production control fails when evaluation, monitoring, and auditability are added after deployment.
- It shows how missing evidence, weak ownership, and incomplete monitoring create operational and audit risk.
- It connects Azure AI control gaps to enterprise consequences such as rework, delayed releases, human review burden, and incident remediation time.
- It presents a production control model built around evaluator design, behavioral monitoring, evidence-chain auditability, release gates, and feedback loops.
Introduction
At 9:14 on a Monday morning, a customer operations lead asks why yesterday’s Azure AI answer changed.
The application is live. Latency is acceptable. Token spend is within the expected band. The team can show that the endpoint responded, but it cannot show whether the answer met the business standard, which retrieval passages shaped it, or which control should have caught the change before a user did.
Some teams will say this is just the normal friction of moving AI into production. That is partly true. Non-deterministic systems will always require tolerance for variation. The harder issue is that variation becomes ungovernable when evaluation, monitoring, and auditability were treated as post-deployment work.
Azure AI monitoring and evaluation should be designed as part of the production control model. Microsoft describes evaluation, production monitoring, traces, logs, model outputs, and quality and safety signals as part of the AI application lifecycle. The enterprise decision sits above those capabilities: what must be measured, retained, reviewed, escalated, and owned before the system influences more work.
Production AI Control Breaks When Deployment Success Is Treated As Readiness
A production release proves that the system runs; it does not prove that the system can be explained.
That distinction feels uncomfortable because most delivery programs are built to celebrate go-live. The platform team can show deployment status, endpoint health, identity configuration, and error rates. A business owner asks a different question: was the answer acceptable for this workflow, and who owns the decision when it was not?
The pattern in production reviews is that platform engineering inherits accountability for behavior it did not define. The model endpoint, prompt flow, retrieval layer, and application telemetry may all function, while no one has agreed what an acceptable answer looks like for a specific process. That leaves engineering watching infrastructure while risk, compliance, and business process owners ask about judgement, evidence, and accountability.
Microsoft Foundry architecture guidance separates resource-level metrics from project-level signals such as evaluation run outcomes, agent invocation counts, and diagnostic logging. That separation matters because production control sits across both layers. Infrastructure health is necessary, but it is too narrow for a system whose business effect depends on output quality and traceability.
For enterprise AI estates, production control depends on the same Azure foundation decisions that shape Microsoft Azure cloud architecture services: network boundaries, identity, data paths, logging, and operating controls.
Retrofitted Control Becomes Architectural Debt, Not Just Extra Monitoring
Retrofitting control onto production AI is expensive because the missing work usually sits inside the application and operating model, not on top of it.
A fair objection is that teams can add monitoring after launch. They can. The question is what the monitor can actually see. If prompt versions, model deployment names, retrieval context, tool calls, user intent, evaluator results, and human review actions were captured from the start, remediation can focus on thresholds and reporting. If those records are partial, the team must change instrumentation while users continue depending on the workflow. If the system records only infrastructure telemetry, the workflow has to be redesigned so future outputs can produce evidence.
What this looks like in practice is that the most disruptive retrofit is rarely the dashboard. The disruption comes from changing production data capture after users have been told the application is stable. More logging can trigger privacy review, storage redesign, retention policy changes, access-control work, and new incident routes. Evaluation also changes release management because prompts, retrieval configuration, model versions, and tool definitions now need approval paths and rollback logic.
The cost is time because engineering has to instrument what was omitted. It is disruption because business owners have to define acceptable output after user expectations already exist. It is architectural debt because a system built without trace IDs, version binding, evaluation datasets, and retention rules cannot produce reliable evidence without redesign.
This retrofit pattern is one reason why Azure OpenAI pilots fail in production: the system proves useful before the enterprise has designed the control model required to run it at scale.
Evaluation Only Works When Acceptable Output Is Defined Before Scale
Evaluation fails when “good output” remains a preference instead of a business rule.
The objection is easy to anticipate: generative AI output cannot be judged like deterministic software. That is true. It also misses the operational point. Enterprises do not need every output to be identical. They need evidence that variation stays within the limits of the workflow.
The consistent gap across Azure AI deployments is vague approval language. A business team says the answer should be accurate, safe, useful, and grounded. Those words cannot govern production behavior until the failing cases are named. Accuracy against which source. Safety for which user group. Usefulness for which workflow. Grounding against which approved corpus. Escalation after which threshold.
Microsoft Foundry supports built-in evaluators for quality, RAG-specific measures, safety and security, and agent measures such as tool call accuracy and task completion. It also supports custom evaluators for domain needs. The enterprise still supplies the judgement criteria.
For a knowledge assistant, acceptable output may require groundedness, relevance, completeness, citation quality, and refusal behavior. For an agent that calls internal tools, acceptable output also includes tool selection, parameter accuracy, task completion, and safe stopping conditions. For a workflow that touches finance, healthcare, legal, or customer-impacting decisions, acceptable output includes evidence that a human can review and override the recommendation.
Evaluator design belongs inside the same operating discipline as model deployment, monitoring, and lifecycle control. Production teams should connect it to broader Azure Machine Learning practices rather than treating evaluation as an isolated review step.
Monitoring Fails When It Watches Infrastructure And Misses Behavior
A production AI system can be healthy by cloud metrics while failing by business standards.
That sounds harsh only if monitoring is treated as a platform concern. Token consumption, latency, request count, and error rate help the platform team run the service. They do not show whether answer quality declined after a retrieval index update, whether users keep correcting the same class of response, or whether an agent’s tool calls are failing in ways that produce incomplete work.
Enterprise teams typically discover that monitoring starts with the signals Azure and Application Insights expose quickly. That creates a sense of coverage before the system has behavior-level visibility. The team can see traffic volume and errors, but it cannot see whether the AI remains fit for the workflow it now influences.
Microsoft describes agent monitoring through operational metrics, evaluation outcomes, continuous evaluation on sampled responses, scheduled evaluations, red-team scans, and alerts for latency, token usage, evaluation scores, and red-team findings. Those signals become control only when they map to decisions.
A groundedness decline in a high-volume workflow should not be handled like a token spike in a low-risk internal assistant. A prompt injection path in an agent connected to internal systems may require tool restriction, prompt hardening, retrieval filtering, or release rollback. A repeated evaluator failure may require business owner review before the workflow expands.
When monitoring exposes drift or quality decline after rollout, the operating pattern resembles the one described in the analysis of Copilot and Azure AI output degradation.
Auditability Collapses When The Evidence Chain Is Missing
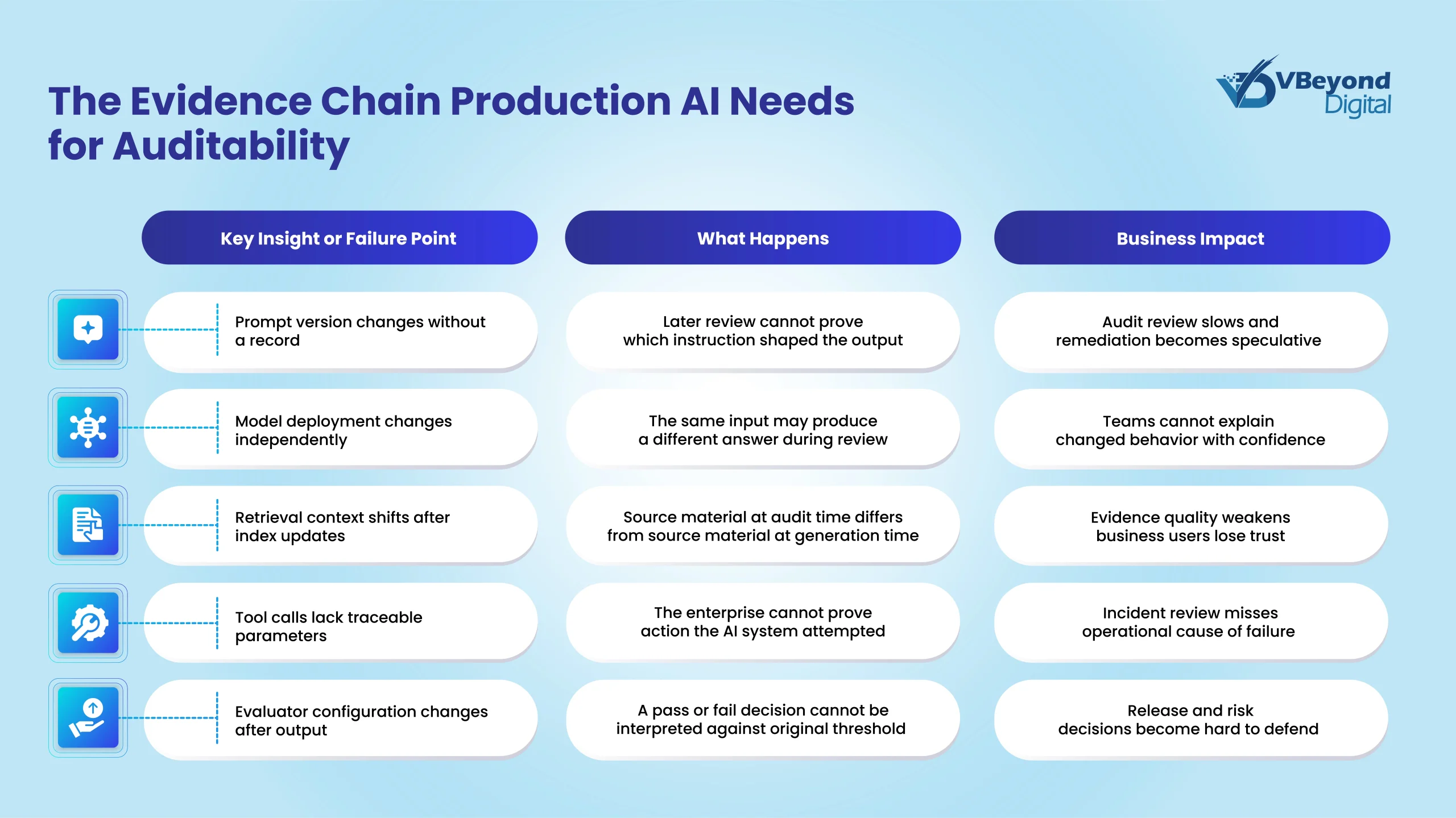
Auditability fails when the enterprise can see the final output but cannot reconstruct the conditions that produced it.
A reasonable objection is that most teams do keep logs. The issue is not whether logs exist. The issue is whether the logs bind the output to the exact prompt template, model deployment, retrieval snapshot, evaluator version, tool call, and human review state that existed at the time of generation.
The audit gap usually appears months after launch. A user challenges a response. A business owner asks why an AI-assisted recommendation changed. A risk reviewer asks which data source supported the answer. The platform team can retrieve fragments, but the fragments do not recreate the decision path.
To reproduce an AI output for audit purposes, the enterprise needs a versioned evidence chain. The record must bind the user request, system prompt, application prompt, model deployment identifier, retrieval query, retrieved documents or chunk IDs, tool calls, evaluator outputs, safety filter outcomes, and human review decision to the generated output. If retrieval content changes, the audit record needs the retrieved context or a reference to an immutable version. If prompts change, the prompt version must be stored. If evaluators change, the evaluator configuration and threshold must be recorded with the result.
Microsoft’s transparency note for Foundry Agent Service describes AI systems as including the technology, the people who use it, the people affected by it, and the environment where it runs. It also describes traceability through instrumentation and logging, including prompts, model steps, and tool calls.
The practical decision is blunt. If the organization cannot reproduce the evidence chain, it should pause expansion into higher-impact workflows until logging, versioning, retention, and review ownership are corrected. The risk appears whenever the business needs to explain a decision and cannot.
Control Maturity Depends On Owners, Thresholds, And Release Gates
Production AI control matures when evidence changes action.
Some leaders will argue that tool coverage should be enough. It helps. It still leaves a gap if no one owns the decision triggered by a failing evaluator, a changed retrieval index, or a tool permission update.
Control models become effective when platform engineering stops acting as the sole owner of AI behavior. Platform teams own instrumentation, deployment, integration, and telemetry. Application owners own workflow fit. Business process owners own acceptable outcomes. Security owns misuse and access concerns. Risk and compliance teams define evidence expectations where their review applies. Executive sponsors own tolerance for residual risk.
The NIST AI Risk Management Framework page says the framework helps organizations incorporate trustworthiness considerations into the design, development, use, and evaluation of AI products, services, and systems. The same page notes an April 7, 2026, concept note for trustworthy AI in critical infrastructure. That lifecycle framing is useful because production control does not begin after delivery.
A prompt update should pass evaluation before release. A retrieval index change should trigger regression review. A tool permission change should go through access review. A repeated evaluation failure should route to an accountable owner. A high-impact workflow should retain enough evidence for later review.
Azure AI control also lives after go-live, where alert review, evaluation runs, logging retention, access changes, and incident response become recurring work. Enterprises deciding how much of that operating load should remain internal can use Azure managed services to define which control activities need external operational support.
Control maturity also depends on feedback loops that improve the system rather than only reporting failure. Evaluation results should feed prompt refinement and release gating when recurring output defects appear. Monitoring signals should trigger remediation when behavior changes, and in some cases, they should trigger retrieval updates, model deployment changes, tool permission review, or rollback. Test datasets should change as workflows change, users learn how to ask differently, and the risk profile shifts. Those feedback loops should connect to business KPIs such as evaluator pass rate by workflow, human override rate, and AI-related incident remediation time.
Controlled Azure AI Can Prove Quality, Explain Change, And Reconstruct Failure
The Monday morning question is still the test: why did the answer change, and what control should have caught it?
Controlled production AI can answer because evaluation criteria were defined before scale, monitoring signals route to owners and remediation, and auditability preserves the versioned context needed to reconstruct decisions after prompts, models, tools, and retrieval content change. That does not make AI deterministic. It makes production behavior explainable enough to govern.
The implication for the Head of AI platform engineering is practical. Before the next rollout, workflow expansion, or executive assurance review, the Azure AI estate should be tested against three questions: can it prove output quality, can it explain changed behavior, and can it reconstruct failure? If the answer is partial, the priority is correcting the control model before scale turns missing evidence into rework.
VBeyond Digital can assess whether existing Azure AI deployments are controllable in production. The assessment reviews evaluation, monitoring, auditability, ownership, escalation paths, and control evidence, then identifies where the enterprise has designed control into the system and where retrofit risk is building.
The system should be able to answer for itself.
Design Integration With Less Risk
FAQs (Frequently Asked Question)
Azure AI monitoring and evaluation needs design work before scale because the system must capture the evidence required for later control. If the application does not retain prompt versions, retrieval context, evaluator results, trace IDs, and human review records, a later dashboard cannot recreate what the system never recorded.
The real cost is rework across application instrumentation, logging policy, test data, release management, ownership, and business review. The most disruptive cost comes from changing live workflows after users already depend on them. That creates delay, review friction, and architectural debt.
An enterprise can reproduce an AI output only when the original output is bound to versioned context. That includes the prompt, model deployment, retrieved content, tool calls, evaluator configuration, safety result, timestamp, trace ID, and human decision state. If any of those can change without being preserved, the audit trail is incomplete.
Azure AI monitoring should track behavior that changes business risk. That includes output quality, groundedness, failed tool calls, safety results, evaluator scores, repeated user correction, exception volume, retrieval failures, and human override patterns. Infrastructure metrics still matter, but they do not prove the AI system remains fit for its workflow.
A production AI control assessment reviews whether each Azure AI deployment has defined evaluation criteria, monitoring signals, audit evidence, control ownership, escalation routes, and release gates. It also identifies where missing telemetry or versioning will require redesign before broader rollout.
